
Optimizing Performance with LRU Cache Implementation in Python

As a software developer, you strive to create efficient and scalable applications that handle large amounts of data seamlessly. Caching mechanisms play a pivotal role in achieving this goal by temporarily storing frequently accessed data, reducing retrieval times, and enhancing overall performance. Among these caching strategies, the Least Recently Used (LRU) cache stands out for its effectiveness in managing high-traffic environments.
In this post, we'll explore the implementation of an LRU cache in Python, a versatile programming language widely used for web development and data science applications. By understanding the LRU algorithm and its practical implementation, you'll gain insights into optimizing data access and enhancing the performance of your Python applications.
LRU Cache: A Brief Overview
The LRU cache operates on the principle of prioritizing recently accessed data, assuming that items accessed more frequently are more likely to be needed again in the near future. When the cache reaches its capacity, it evicts the least recently used item to make space for new data. This approach ensures that the cache remains efficient, prioritizing frequently accessed data while minimizing unnecessary data storage.
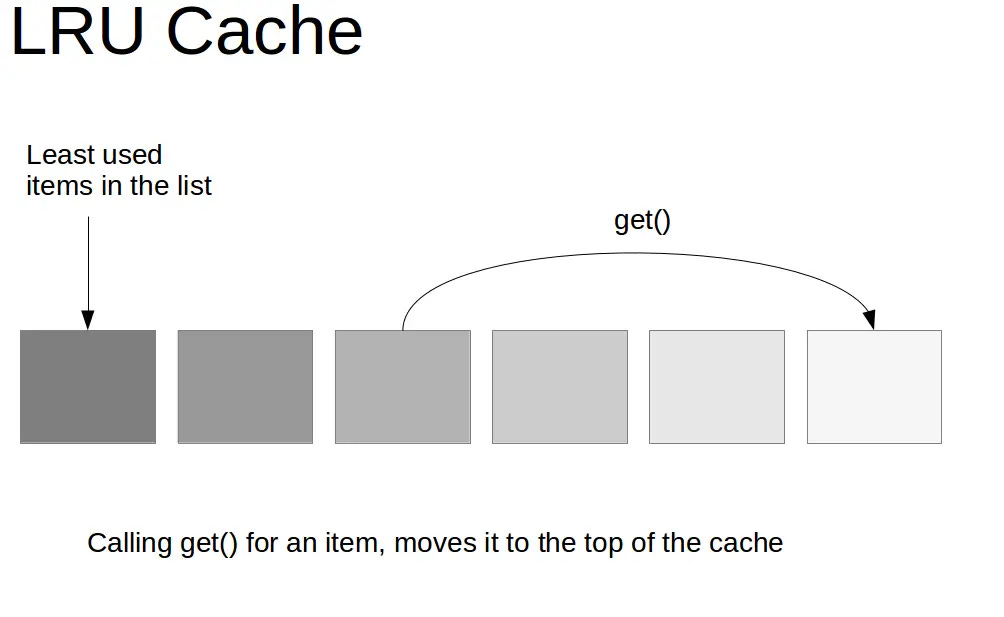
Implementing LRU Cache in Python
To implement an LRU cache in Python, we can utilize a combination of a doubly linked list and a hash map. The doubly linked list maintains the order of usage, with the most recently used item at the head and the least recently used item at the tail. The hash map provides a fast lookup mechanism to access items directly.
Here's a simplified code snippet demonstrating the LRU cache implementation:
class Node:
def __init__(self, key, value):
self.key = key
self.value = value
self.next = None
self.prev = None
class LRUCache:
def __init__(self, capacity):
self.capacity = capacity
self.cache = {}
self.head = None
self.tail = None
def get(self, key):
if key in self.cache:
node = self.cache[key]
self.moveToHead(node)
return node.value
else:
return None
def put(self, key, value):
if key in self.cache:
self.cache[key].value = value
self.moveToHead(self.cache[key])
else:
if len(self.cache) == self.capacity:
self.removeLeastRecentlyUsed()
node = Node(key, value)
self.cache[key] = node
self.addToHead(node)
def moveToHead(self, node):
if node == self.head:
return
if node.prev:
node.prev.next = node.next
if node.next:
node.next.prev = node.prev
if node == self.tail:
self.tail = node.prev
node.prev = None
node.next = self.head
self.head.prev = node
self.head = node
def addToHead(self, node):
if self.head is None:
self.head = node
self.tail = node
else:
self.moveToHead(node)
def removeLeastRecentlyUsed(self):
if self.tail:
node = self.cache.pop(self.tail.key)
self.tail.prev.next = None
self.tail = self.tail.prev
This code snippet provides a basic implementation of an LRU cache in Python. You can extend this implementation to include additional features, such as setting expiration times for cached items or handling concurrency issues.
Benefits of LRU Cache
The LRU cache offers several benefits for improving application performance,
including:
Reduced Latency: LRU caching minimizes the need to retrieve data from the original source, reducing latency and improving response times.
Improved Scalability: By prioritizing frequently accessed data, LRU caching allows applications to handle larger amounts of data without significant performance degradation.
Efficient Memory Usage: LRU caching ensures that frequently used data remains in memory, while less frequently used data is evicted, making efficient use of available memory resources.
Conclusion
Implementing an LRU cache in Python is a valuable technique for optimizing data access and enhancing the performance of your applications. By understanding the LRU algorithm and its practical implementation, you can create more efficient and scalable software solutions.